李传志
(吉林工业经济学校,吉林 吉林132000)
快速存取记录器(QAR)是一种机载飞行数据记录仪,相比以往较为常见的黑匣子,前者更具时序性,并且拥有容量大、参数多等优势[1]。但由于QAR 数据数量较多,传统关系数据库难以高效完成数据存取,所以急需一款新型QAR 数据储存系统,实现QAR 数据的快速存取。本文以HBase 技术为基础,构建一种QAR 数据储存系统。
1 数据储存模式设计
1.1 参数主题划分
通过与专业人士探讨分析,结合航空公司关注问题,本文将QAR 数据分为安全分析、航迹描绘、节省燃油、发动机状况、预测、飞行员操作分析及其他等七个主题。安全分析主题主要参数包含无线电高度、高度、风向、航向、偏流角、攻角、地速、V1速度、V2 速度、Vr 速度、Vref 速度、左右油门反推位、左反推伸出、左反推转换、打开A/T、A/T 脱开、APU 启动和A/P 关断;航迹描绘主题主要参数包含经度、纬度、高度、航向和偏流角;节省燃油主题主要参数包含地速、空速、发转速、左发转速、N1、N2、马赫、飞机重量、左右主油箱燃油流量、扰流板位置、选择高度、选择垂直速度、选择马赫速度、选择空速和大气静压;发动机状况主题主要参数包含高度、高低压转子转数、马赫数、油门杆角度和风扇进口温度;预测主题主要参数包含倾斜角度、俯仰角度、滑油压力、EGT 温度、左右油箱燃油流量、VOR 频率、TCAS状态、垂直加速度等;飞行员操作分析主题主要参数包含下降率、偏航角、襟翼度数、着陆速度和速度变化率;其他主题包含未纳入以上主题的参数。
1.2 QAR 数据储存设计
本文设计QAR 数据储存系统主要涉及HBase 表结构设计、Value 表行键设计和预分区设计三方面内容。
HBase 表结构设计:通常情况下,每个QAR 文件在完成译码后均由航班信息、参数信息和参数值三部分内容组成,据此本文将QAR 数据分为航班元信息、参数元信息和参数值三大类。通过QAR 数据类别和超限事件进行需求分析,本文分别设计出航班元信息表(FI)、参数元信息表(PI)、航班参数索引表(I)和数据值表(V)四个表。FI 表行键由航班号和航班日期组成,列簇为F_CF,共包括起飞落地时间、起飞落地机场、机尾号、航空公司及航班序列号等七列。PI 表行键由参数名称组成,列簇为P_CF,共包括参数简称、单位、主题及参数序列号等四列。I 表行键由航班号、航班日期和参数名称组成,列簇为I_CF1和I_CF2,I_CF1 包括航班参数编号一列,I_CF2 包括航班参数对应MD5 值一列。V 表行键由航班号、航班日期、参数名称、参数主题及参数取值对应时间组成,列簇为V_CF,共包括00~59秒数据值六十个参数[2]。
Value 表行键设计:本文设计V 表行键主要由五个部分组成,为能尽量缩短行键长度,以减少储存空间占用,本文利用MD5 散列对V 表行键进行改进,行键前4 个字节设置为航班号、航班日期及参数主题,行键中间8 个字节分别设置为航班序列号和参数序列号,行键后4 个字节设置为参数取值对应时间,包括小时位与分钟位。
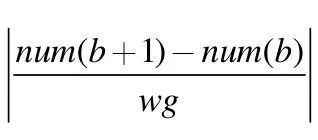
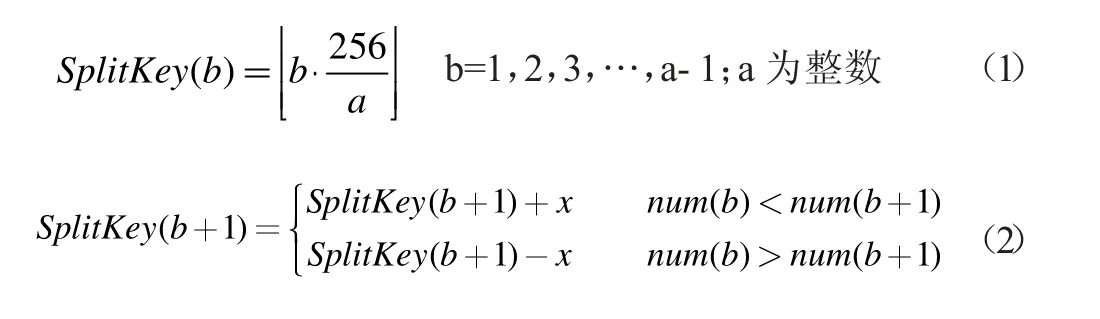
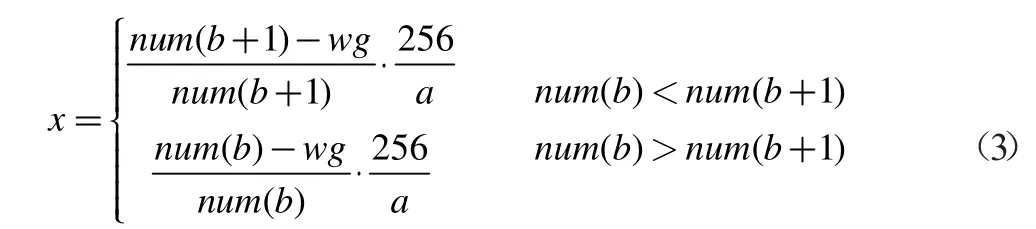
1.3 储存与查询过程实现
由于FI 表、PI 表和I 表三者储存原理大致相同,因此本文仅对FI 表储存原理过程进行描述。QAR 数据在完成译码处理后,其路径会被记录在本文文件中,需要使用QAR 文件时,仅需读取存储路径信息的文本文件,即可打开QAR 文件,随后对QAR 文件表头第一、二行内容进行解析,即可将FI 表中的航班元信息全部读取出来,其中航班号由航班公司二位代码和航班序列号组成,航班日期则按照yyyymmdd 格式进行提取,机尾号由字母B 和阿拉伯数字组成,机场四字码代表起飞落地机场,起飞落地时间选用12 小时制来表示,根据AM和PM区分上下午。对QAR 文件存储路径进行读取时,会对此路径位置进行记录,并生成4 字节数字序列号,并将其赋值于航班序列号。随后再将QAR 文件表头和FI 表相关数据以put(List
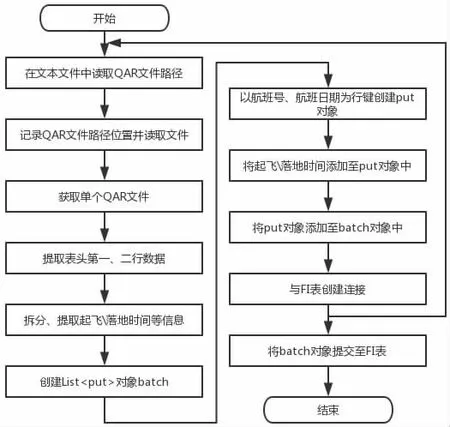
图1 FI 表数据储存流程示意图
对于数据查询,将航班号、参数名称、起始查询时间和终止查询时间分别设定为f、p、t1和t2,在进行飞行品质监控分析过程中,查询条件则可表示为q(f,p,t1,t2)。比如在2020 年1 月1日航班号为AB2259 的航班,k 时间在10:20 至10:22 的地速ground speed 取值查询可表示为q(“AB225920200101”,“ground speed”,“1020”,“1022”),经行键过滤器得到I 表对应列值和MD5 值,随后再将两列值组合获得V 表行键高12 字节,接着将查询到的参数时间范围添加到V 表行键低4 字节中,进而获得查询V 表行键范围,通过设置二级过滤器,对V 表进行过滤,最后对扫描对象进行创建,再将二级过滤器添加至扫描器对象,进而获得查询结果。
2 实验结果及分析
2.1 设置实验环境
抽取2020 年上半年某航空公司200 个航段QAR 数据文件作为实验数据,实验集群包括一个主节点和两个虚拟节点,集群整体搭建服务器内存为32G,磁盘储存空间为3T,服务器型号为PowerEdge R740。单节点各分磁盘空间50GB、内存1GB,选用单核CPU,Hadoop 集群选用Hadoop2.7.6、Zookeeper3.4.13及HBase2.6.5,分区b 设置为27,集群HDFS 复制因子设置为2。
2.2 QAR 数据储存分布
于QAR 文件数量递增条件下进行QAR 数据储存分布效果实验,设置5 组测试,QAR 文件个数分别使用30、90、120、160和200 个。实验结果显示,各个数据节点数据增长趋势大致相同,同时利用MD5 散列改进的V 表,可提高数据分布的离散性,进而避免数据写入时发生热点问题,此外,通过划分出27 个分区,也保证了各分区数据数量相对平衡,进而有效避免数据倾斜的发生。
2.3 QAR 数据查询
通过对实际飞行品质进行需求分析,本文共设置3 种查询场景完成QAR 数据查询实验。实验一是对指定航班指定参数5分钟内300 个参数进行查询,实验二是对指定航班指定主题下5 个不同参数1 分钟内60 个连续数据进行查询,实验三是对指定航班5 个不同主题下指定参数1 分钟内60 个连续数据进行查询,每个实验均进行20 次。实验结果显示,实验一、实验二及实验三进行20 次查询的平均耗时分别为299.63ms、1786.40ms及1909.75ms,表明本文设计储存系统更适合对指定参数一段时间内连续取值序列进行查询。
3 结论
本文设计基于HBase 技术的QAR 数据储存系统可将QAR数据相对均匀的储存在HBase 集群当中,降低资源消耗,在数据查询方面也可实现快速查询,特别是在QAR 参数取值序列场景中查询效率极高。



