李洁
(广西科技师范学院 数学与计算机科学学院,广西 来宾546199)
降雨是一种常见的自然现象,一个地区降雨量的多少直接影响和制约着国民经济的发展和生产生活安全。近年来,水灾和旱灾导致的国民经济损失日益加大。因此,为了有效防治、管理和控制灾情,准确的降水预报具有现实的指导意义[1]。
然而,降雨自然现象的形成是一个复杂的过程,受地表、温度、湿度、人文因素等多种因素影响,使得预测变得更加困难。单层前馈神经网络(SLFN)以其良好的学习能力在许多领域得到了广泛的应用,然而传统的学习算法,具有训练速度慢,容易陷入局部最小值,学习率敏感等特点[2]。本文采用一种新的SLFN 的算法——极限学习机(ELM)对广西降雨历史资料进行训练建模预测,通过计算预测结果的均方根误差进行模型评估。

其中,wi和bi是隐藏层节点参数,g(wi,bi,x)是激活函数,该函数是一个满足ELM 通用逼近能力定理的非线性分段连续函数,本模型使用Sigmoid 函数,故g 函数为:
1 ELM 原理

1.1 ELM 模型结构[3]
极限学习机(ELM)是一种针对单隐含层前馈神经网络(Single-hidden Layer Feedforward Neural Network,SLFN)的新算法。由三层节点构成,分别为输入层、隐含层和输出层。其结构如图1 所示。
将wix+bi代入公式x 即可。
数据经隐层后进入输出层,根据图1 及公式,则用于“广义”的单隐藏层前馈神经网络ELM 的输出是:

1.2 训练过程
ELM 训练SLFN 可分为两个主要阶段:
1.2.1 随机特征映射
初始化随机产生输入层权重和隐藏层偏置,利用一些非线性映射作为激活函数,将输入数据映射到一个新的特征空间。与传统的BP 神经网络相比,ELM 隐藏层节点参数ω 和b 根据任意连续的概率分布随机生成,与训练数据无关,而不是经过训练确定的,从而在相比在效率上占有较大优势。随机确定好参数ω 和b 后,根据公式(1)和(2)计算出隐层输出H。
1.2.2 线性参数求解
为了得到在训练样本集上的较好β, 需要保证训练误差最小。采用网络输出Hβ 与样本期望输出T 的最小误差平方和最小为目标函数,对连接隐藏层和输出层权值β 进行求解,目标函数为:
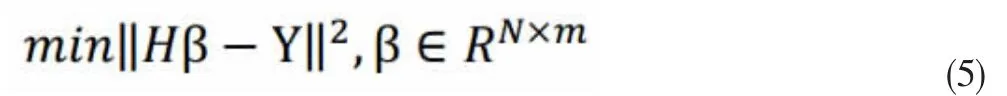
其中H 是隐藏层的输出矩阵,T 是训练数据的目标矩阵:
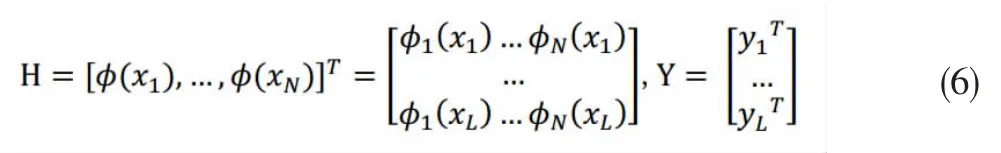
由矩阵论得公式(5)的最优解为:

其中H+为矩阵H 的广义逆矩阵。当H+H 为非奇异时使用正交投影法,利用公式(8)即可求解得H 的广义逆矩阵H+。

2 实验结果与分析
2.1 数据来源
本文选取广西三区2003-2008 年这6 年期间5 月份广西水文监测站点监测到的实际测量因子作为实验样本,用2003-2007 前5 年5 月的数据(包括30 个输入因子,1 个输出)作为ELM 训练样本,预报三区2008 年5 月的逐日降水量。
2.2 ELM 预报生成
将五月三区的179 个数据样本分成两组,前148 个用于训练,后31 个用于测试。将数据标准化处理,归一到单位方差和零方差。随机产生偏差,置隐层节点数50,采用公式(3)作为激活函数,将148 个训练样本输入到ELM 网络模型,训练出权重,用训练得到的权重计算出31 个测试样本的输出值。
图2 是ELM 对前148 个样本的模型拟合效果。图3 是后31个样本,即2008 年5 月31 天逐日预报效果及每天误差值。图中,Actual rainfall 代表站点实测雨量,ELM fitting 代表样本拟合 值,ELM prediction 是ELM 模 型 预 测 值,t213 prediction 是T213 模式预报值。

图2 ELM 对5 月三区148 个建模样本拟合效果
2.3 ELM 预报结果分析
为分析模型优劣,将ELM 模型结果T213 模式进行分析对比,表1 给出预测2008 年5 月三区结果的各项指标。
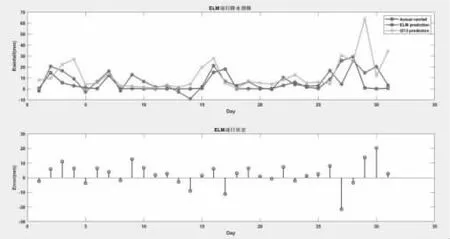
图3 ELM 模型对5 月三区31 天的逐日预报对比及误差对比

表1 ELM 预报与T213 预报的各项指标误差对比分析
从表1 可以看出,本文建立ELM 模型在均方根误差、最大绝对误差两个重要衡量指标上,均优于T213 模式。ELM 模型能获得更好的预测结果,预测精度较高。
结束语
可见,即使随机生成隐藏层节点及偏置,ELM 仍保持了SLFN 的通用逼近能力。实验结果表明,极限学习机具有训练参数少、学习速度快、泛化能力强的优点,用在降雨气象建模上具有良好的效果。后续研究中为进一步提高传统极限学习机的稳定性和泛化能力,可以考虑优化等式约束的极限学习机,在目标函数中增加权值范数的约束项来重新求解输出权重。



