邢 瑾
(上海勘测设计研究院有限公司,上海 200434)
建筑物作为城市的主要组成部分,城市规划、智慧城市等方面的不断发展对建筑物信息的提取研究提出了更高要求[1]。随着遥感技术的不断进步,基于高空间分辨率遥感影像的建筑物信息提取成为目前遥感和摄影测量领域的研究热点[2]。建筑物信息提取方法主要分为以像元和对象为研究对象的两大类,相对于存在严重“椒盐”现象的基于像元分类方法[3],面向对象分类方法具有融合相邻同质像元光谱、纹理、几何形状和上下文等特征信息,以实现目标对象的高质量提取[4]。
近年来,国内外大量学者针对地物信息提取多采用面向对象的机器学习分类算法,随机森林作为较为热门的机器学习算法之一,在建筑物提取方面发挥着重要作用。郜燕芳等[5]通过对比不同训练样本比例下随机森林和支持向量机方法对城市不透水面的提取研究,表明随机森林方法优于支持向量机方法;宋茜[6]应用RF、SVM 分类器训练并获取黑龙江省北安市农作物空间分布,结果表明对于具有高维特征空间和多分类等问题上,RF 的泛化和抗噪能力要优于SVM;Novack 等[7]通过对巴西圣保罗城区的地表覆盖分类,对比分析了支持向量机、C4.5 决策树、分类回归树、随机森林等4 种方法,试验结果表明随机森林的分类精度最高;M.Pal[8]对随机森林分类器和支持向量机在分类精度、训练时间和用户自定义参数方面进行比较,两者分类效果相当,随机森林所需的用户自定义参数数量少于支持向量机所需的数量,易于定义。针对以上已有研究,本文以德国恩茨河畔法伊欣根某部分城区为例,探讨基于随机森林(RF)在面向对象影像分析方法中进行建筑物信息提取的技术。
1 研究区概况
研究区位于德国恩茨河畔法伊欣根某部分城区,所使用数据为Open Topography 网站下载的官方测试数据,该数据已经过几何校正等预处理,其空间分辨率为0.9m,由近红外、红光和绿光3 个波段组成,影像尺寸为1024 像素×1024 像素,区域范围约为0.85km2(图1)。该研究区主要有建筑物、草地、树木、道路、裸地五种地物类型。本文研究的主要对象是建筑物,此研究区内的建筑物颜色不一、形状多样。

图1 研究区影像
2 研究方法
面向对象的影像分析方法主要包括影像分割、特征选择和对象分类三个板块。首先,选择合适的影像分割方法将影像根据像元的同质性和异质性分割成多个影像对象;其次,选取有利于对象分类的影像对象的光谱、纹理、几何形状和上下文等特征参与影像对象分类;最后,选取合适分类方法及分类参数实现影像对象分类。
2.1 影像分割
影像分割是将影像分成若干个具有相似特征的多边形对象的过程。文献[9]中Baatz 和Schape 提出的分型网络演化算法作为目前最为常用且最具特色的分割技术。该算法主要通过尺度因子(Scale)、形状因子(Shape)和紧凑度(Compactness)三个参数变量组合决定地物在影像中的分割结果[10]。采用试错法进行分割参数组合,具有一定的主观性和盲目性,而Liu 等[11]设计的不一致性评价法,通过综合参考多边形与分割对象之间的几何关系差异和代数关系差异,提出了PSE、NSR 和ED2 三个分割质量评价指数,可定量化评价分割质量。
2.2 特征优选
在面向对象的影像分类方法中,构建合适的特征空间对分类结果具有重要作用。特征空间中特征种类组合及维度的选择对分类结果均有一定的影响及作用。根据研究区以及特征优选方法现状,本文预采用Relief F 和PSO 混合特征选择算法进行特征优选。Relief F 算法是一种过滤式多分类特征选择算法,通过计算各特征和类别的相关性赋予不同权重,并根据权值大小判断特征重要性[12]。POS 是一种基于群体协作的随机搜索算法,通过群体汇总个体之间的协作和信息共享使整个群体的运动在问题求解空间中产生无序到有序的演化过程,从而获得最优解[13]。
2.3 随机森林
随机森林是由Breiman 等提出的一种机器学习算法[14],它是通过集成学习的思想将多棵树集成的一种算法,基本单元是决策树,而其本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。实际上是一种特殊的bagging 方法,将决策树用作bagging 中的模型。随机森林中的每颗决策树估计一个分类,这个过程称为“投票”,理想情况下,根据每颗决策树的投票结果,选择最多投票数作为分类结果。随机森林的参数设置比较简单,只需要定义构成随机森林的决策树的深度即可。
3 结果与讨论
3.1 最优分割对象
本文采用eCognition 商业软件中的分型网络演化算法(Fractal Net Evolution Approach,FNEA)完成研究区影像的多尺度分割,基于Liu 等[11]提出的不一致评价法分割参数优选模型。根据研究区建筑物实际特点,将影像分割的尺度因子范围设为10-160,步长10;形状因子和紧凑度因子均设为0.1-0.9,步长0.1。通过ED2 与尺度因子的相对关系,确定影像的最优分割参数组合,尺度因子:90、形状因子:0.4、紧凑度因子:0.6。从而得到最优分割结果图(图2)。

图2 影像最优分割结果图
3.2 最优特征空间
为了构建全面且最优的特征空间,本文分别选取了9 个光谱特征、28 个纹理特征、15 个几何特征以及4 个自定义特征,共计56 个特征组成基本分类特征空间。以此为基础,基于WEKA 平台,按照Relief F 和PSO 混合特征选择算法实现特征优选,优选出建筑物分类的18 维最优特征空间组合(见表1)。
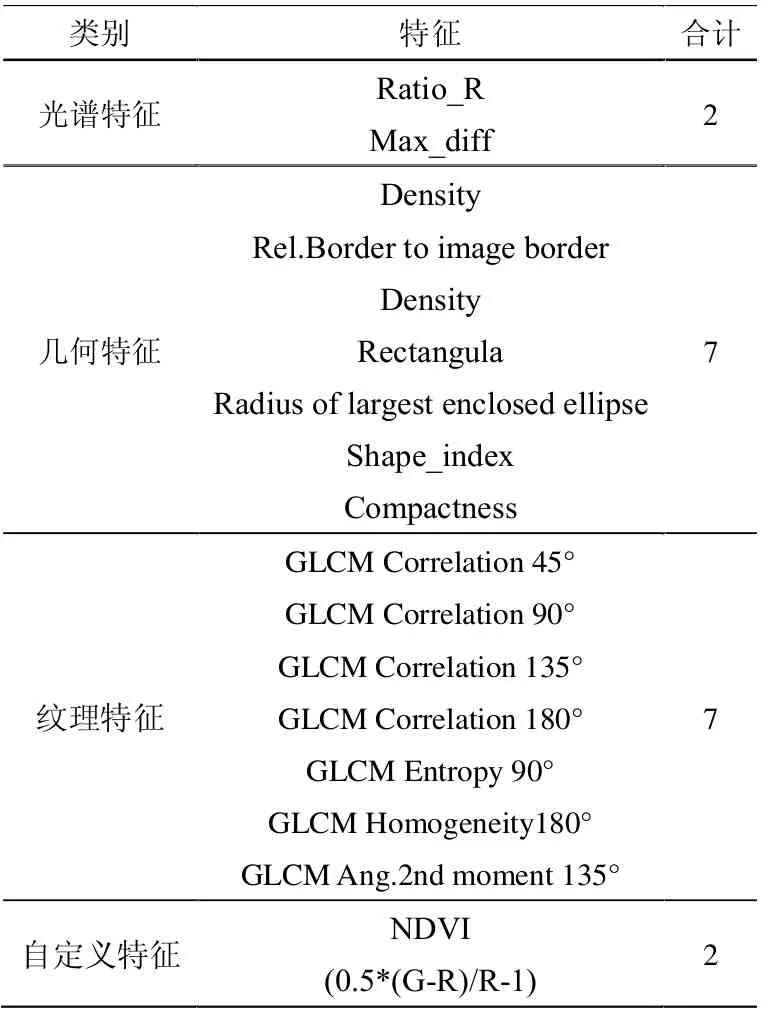
表1 最优特征空间组合
3.3 建筑物提取
随机森林算法的分类精度主要取决于决策树的最大深度。为了尽可能地提高分类准确性,本文对决策树最大深度参数设置不同数值进行了测试和评估,通过比较不同最大深度下的随机森林OOB 误分率,来选择最佳的深度值(图3)。从分类结果中可以发现,当随机森林的最大深度为5 时,OOB 的误分率最低,这也符合Breiman 关于特征自己维度的最优值约等于所有特征个数的算术平方根的结论。而当决策树的最大深度为11 时,OOB 的误分率趋向平稳,其模型效果也最好,所有本研究选择随机森林的模型最大深度为5 作为分类参数。
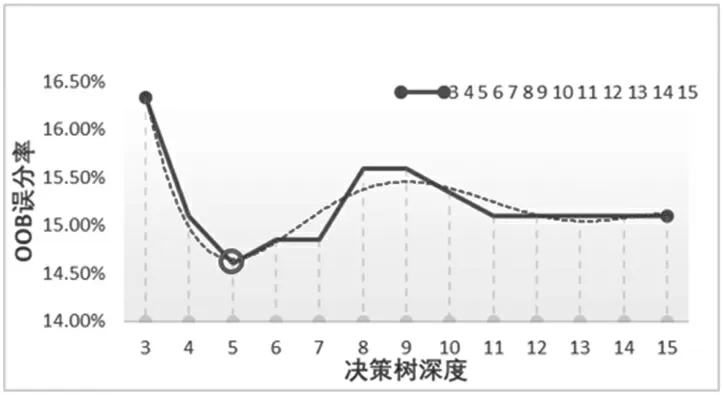
图3 随机森林OOB 误分率和参数的关系
3.4 分类后处理
3.4.1 植被掩膜
研究区中含有大量的树木和草地等植被,植被具有独特的光谱特征,NDVI 是一种被广泛运用的检测植被状况的特征指数,可以很好地利用植被的光谱信息进行植被提取。对研究区进行大量实验,当NDVI≥0.1245 时,可以将植被很好掩膜。
3.4.2 阴影掩膜
研究区中地物高度不一,由于太阳高度原因产生大量的阴影,会对建筑物提取造成一定的影响,为了去除阴影,本文使用影像三波段的均值,不断尝试,最终确定当影像三波段的均值≤45.5 时,可以将阴影很好掩膜。
3.4.3 语义特征优化
经过植被掩膜和阴影掩膜后,会发现仍有许多建筑物对象被归为其他类别,按照建筑物对象与其他对象直接的语义关系进行填洞、边界补充等操作,使建筑物提取效果得到优化。
3.5 精度评价
为评价本文所提方法的分类效果,通过目视解译,查看建筑物的提取情况,定性评价建筑物的提取效果;再选择验证样本进行定量精度评价,得出基于随机森林的面向对象建筑物提取总精度为96.3%,卡帕系数为0.843(表2)。
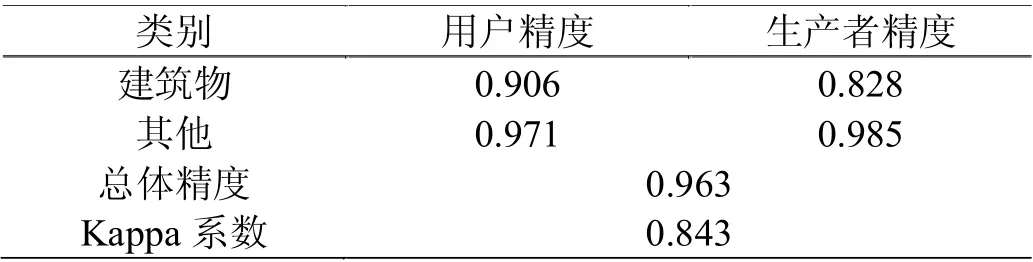
表2 分类精度统计表
图4 为本实验建筑物信息提取的结果图,图中共有15 个建筑物对象,提取结果中也都包含了这15 个对象,且建筑物提取总精度达到96.3%,较以往建筑物提取实验,精度有所提高,说明使用本文所采用面向对象的最优深度随机森林方法较为可信。但从提取的单个建筑物看,存在建筑物的轮廓不够完整的现象,尤其是建筑物的边缘部分被归为其他类别,这可能是由于建筑物边缘部分具有独特的结构所引起的。另外,由于建筑物与裸地相邻,它们的光谱信息极为相近,导致建筑物提取结果中含有部分裸地对象。

图4 建筑物提取结果图
4 结论
本文针对德国恩茨河畔法伊欣根某部分城区的0.9m 高空间分辨率遥感影像,基于随机森林面向对象影像分析的方法提取复杂建筑物。结果表明:随机森林算法能够有效地利用自身适合于高维数据分类的优势,充分挖掘建筑物的光谱、纹理和几何等信息,并对各种特征的重要性全面评估,从而为其他面向对象分类方法提供特征空间构建的依据。建筑物信息提取的总体精度和卡帕系数分别达到96.3%和0.843,实现了建筑物的高精度提取,对复杂情况下的高分辨率遥感影像地物提取具有参考价值,但关于建筑物轮廓细节还有待思考其他方法进行完善。



