杨 勇
(红云红河集团昆明卷烟厂,云南 昆明 650000)
烟草行业是我国国民经济的重要支柱产业之一,为国家建设和社会发展提供了重要的支撑和保障作用。对烟草企业来说,每年有大量的生产、销售数据可供参考和研究,如何利用现有的烟草信息资源来挖掘和掌握市场规律和消费特性,是烟草企业信息化建设的重要内容之一。目前,市场状态瞬息万变,相关信息和数据也是大规模的、动态的、连续变化的,传统统计分析方法已经很难满足现实需要;而大多数生产数据、销售信息、消费行为的多维属性尤为明显。因此,通过多维规则挖掘算法对卷烟生产、销售数据进行分析和探索,运用数字化、信息化方式帮助烟草企业实现高质量发展,打造以大数据为核心驱动要素的产业体系,为高质量发展提供有力支撑,做到精准规划、精准发力、精准营销。
1 关联规则挖掘算法
1.1 数据挖掘的概念
数据挖掘(Data Mining)[1]定义是由U.M.Fayyad等人提出的:它是从大型数据集中提取出人们感兴趣的知识(这些数据集可能是不完全的、有噪声的、不确定的、各种形式存储的),这些知识是先前未知的、对决策有潜在价值的且是隐含的,数据挖掘所提取的知识常用概念、规则、规律和模式等形式进行表示。简单来说,数据挖掘就是指从大型复杂数据中提取和挖掘知识,以满足人们某些实际应用需求。
一个典型的数据挖掘过程应该包括7个步骤[2],如图1所示。

图1 数据挖掘的主要过程
1.2 关联规则简介
定义1[1]数据项与数据集:设I={i1,i2,……,im}是m个不同的项目集合,每一个ik(k=1,2,……,m)称为数据项(Item),数据项的集合I称为数据项集(Item set),简称为项集,项个数称为数据项集的长度。长度为k的数据项集称为k维数据项集,简称为k-项集(k-Item set)。
定义2事务:事务T(Transaction)是数据项集I上的一个子集,表示为TI。每个事务均通过唯一的标识符TID与之相联,不同事务全集构成全体事务集D(或事务数据库)。
定义3数据项集的支持度:设X为项集,B为数据库D中包含X的数量,A为数据库D中包含的所有事务的数量,则数据项集X的支持度(Support)为:
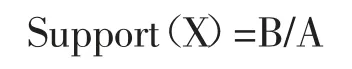
项集X的支持度Support(X)表示项集X的出现次数在事务数据库中所占的比例。
定义4关联规则:关联规则可以表示为R:X→Y,其中X⊆I,Y⊆I,且X∩Y=Ø,它表示如果项集X在某一事务中出现,必然会导致项集Y也会在同一事务中出现。X称为规则的先决条件(前项),Y称为规则的结果(后项)。
定义5关联规则的支持度:对于关联规则R:X→Y,其中X⊆I,Y⊆I,且X∩Y=Ø。规则R的支持度是指数据库D中同时包含项集X和项集Y的数量与所有项集数量之比。
定义6关联规则的置信度:对于关联规则R:X→Y,其中X⊆I,Y⊆I,且X∩Y=Ø。规则R的置信度(Confidence)表示为:
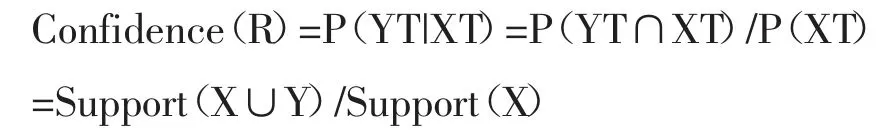
即指数据库D中出现项集X的时候,项集Y也同时出现的概率。
定义7最小支持度和频繁项集最小支持度(Minimum support):表示事先规定的发现关联规则时数据项必须满足的最小支持阈值,它表示数据项集在某种意义下的最低重要性或者重复性,记为min_sup。当满足最小支持度的时候,项集才可能出现在关联规则中,支持度大于最小支持度的数据项集称为频繁项集或者强项集(Large item set);小于最小支持度的项集称为非频繁项集或者弱项集(Small item set)。
定义8最小置信度:最小置信度(Minimum confidence)表示关联规则必须满足的最小可信度,记为min_conf,它表示关联规则的最低可信任性和可靠性。
定义9强关联规则:如果Support(R)≥min_sup且Confidence(R)≥min_conf,则称关联规则R:X→Y,为强关联规则。
1.3 关联规则挖掘的主要流程
关联规则挖掘主要包括以下2个步骤:
第一步,发现频繁项集(Frequent Item set):找出所有支持度大于或等于最小支持度的项集(Item set)或者属性集。
第二步,生成关联规则(Rules):通过频繁项集找到那些置信度大于最小置信度的强关联规则。
关联规则挖掘的基本工作流程如图2所示。
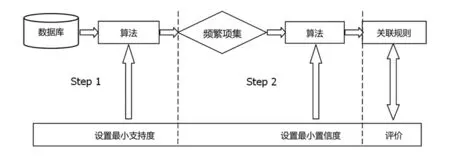
图2 关联规则挖掘的基本流程
2 多维关联规则挖掘
2.1 多维关联规则的概念
多维关联规则是指数据挖掘过程中涉及到多个谓词或者多个属性的关联规则挖掘,这是根据关联规则所涉及到的数据的属性或维度来进行区分的[1]。
多维关联规则又可细分为维间关联规则(inter-dimensional association rule)和混合维关联规则(hybriddimensional rule),这里我们把每个不同的谓词或属性称作维,以此用来对关联规则挖掘的数据复杂程度做划分。
例如:Buys(X,“computer”)→Buys(X,“software”)中只涉及到Buys一个谓词,因此该规则就是单维关联规则,也可称为维内关联规则,即它包含单个不同谓词(Buys)或维的多次出现。
Age(X,“30-39”)^income(X,“40K-50K”)→Buys(X,“computer”)则是涉及Age、income和Buys 3个维度的关联规则,因此我们称这种涉及2个或者多个谓词或维的关联规则为多维关联规则。
多维关联规则中仅出现1次的谓词称为不重复谓词,我们通常把具有不重复谓词或属性的多维关联规则称作维间关联规则,如规则:Age(X,“30-39”)^income(X,“40K-50K”)→Buys(X,“computer”)。如果在多维关联规则中具有重复的谓词,即它包含某些多次出现的谓词,则称这种关联规则为混合维关联规则,如规则Age(X,“30-39”)^income(X,“40K-50K”)^Buys(X,“software”)→Buys(X,“computer”)。
2.2 挖掘多维关联规则的方法
2.2.1 将属性静态离散化[3]
这种方法需要预先定义概念分层,挖掘之前将量化属性离散化,数值属性的值可以用区间标号替换,同时,需要时可将分类属性泛化到较高的概念层。我们可以将每一个属性值看做一个项集,搜索所有相关属性来找出所有的频繁谓词集。一般情况下,可以对单维关联规则挖掘算法进行改进来提高挖掘效率。
2.2.2 挖掘量化关联规则[3]
为了满足某种挖掘标准,我们可以在挖掘过程中进行数值属性的动态离散化,主要方法是使用关联规则聚类系统ARCS来将量化属性用2-D栅格来映射那些满足分类条件的属性,然后搜索栅格发现点簇产生关联规则。
2.2.3 挖掘基于距离的关联规则
根据数据点之间的距离来进行动态属性离散化量化,是基于距离的关联规则挖掘的关键,它紧扣区间的数据语义[4],不允许数值的近似操作。基于距离的关联规则挖掘算法是针对数据分布的不均匀性和局部稠密性导致量化规则无法紧扣属性间数据语义的缺陷进行改进的。该方法主要通过2次遍历算法来挖掘这类关联规则挖掘:第一次遍历数据项集所在的数据库,使用聚类方法找出区间或簇;第二次再次遍历数据库,搜索频繁的且同时出现的簇组,从而以此得到基于距离的关联规则。
3 多维关联规则挖掘在烟草行业中的应用探索
随着信息化的发展,目前在卷烟零售和批发市场中,销售数据越来越全面,已经包含了购买者“所在地区、年龄、职业、收入、所购买卷烟品牌、价位、规格”等多维度信息,这对多维关联规则挖掘算法在烟草行业的应用提供了基础数据支持。同时,我们可以针对品牌信息维度细分到包装颜色(条包、小包)、烟支粗细、长短、滤棒规格(普通、复合、中空、中空复合等)、转接纸颜色、水松纸颜色、焦油含量、香气、吸味等专业层面的信息,从而帮助我们进行更深层次的数据挖掘。
考虑到实际应用中会涉及到混合维关联规则挖掘,因此本文提出2种方法来进行混合维关联规则挖掘:
(1)针对具有重复谓词的多维关联规则,如果每一个事务的重复谓词部分包含内容基本相同,仅是具体数据内容不同的时候,则可以选择在数据预处理过程中进行属性分离,见表1。
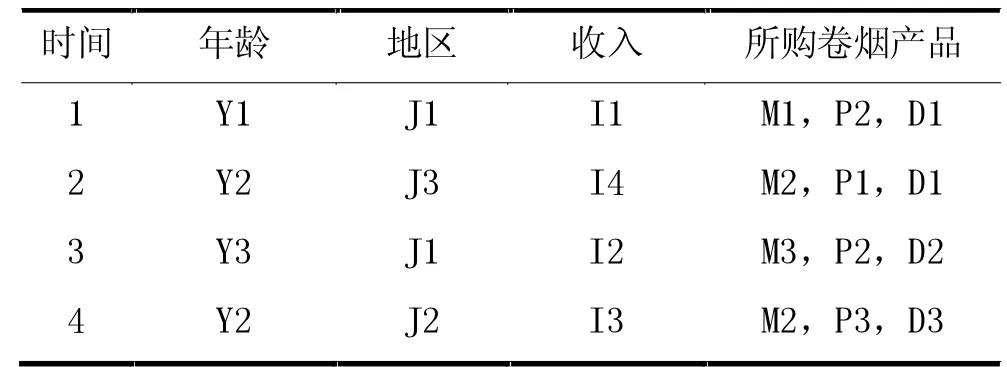
表1 混合维关联规则数据实例1
经过数据预处理得到的结果见表2。这样即可采用关联规则(多维)进行挖掘。

表2 混合维关联规则数据处理结果
(2)如果每行的重复谓词部分包括不同的数据内容时,见表3,则可在进行关联规则挖掘的同时,针对重复谓词部分进行2次单维关联规则挖掘,从而实现混合维关联规则的挖掘,2种方法视具体情况选定。

表3 混合维关联规则数据实例2
通过采用多维关联规则数据挖掘方法,用大量消费者的个人喜好信息和购买习惯数据进行综合分析,勾勒出不同地区、不同时期的消费者的用户画像,为产品设计、新品研发、区域个性化定制、营销策略、经营措施、管理决策等提供支持。
例如:通过多维关联规则挖掘能得到“2020年,某地30-35岁中等收入人群喜欢价位在40-60元、红色简约包装、中支烟、84 mm、中空复合滤棒、焦油含量8 mg、清香”等,对产品区域定制、个性化定制、新品研发等方面提供参考。
4 结束语
综上所述,通过多维关联规则对卷烟生产数据、销售数据进行挖掘,能够针对大量消费者的个人喜好信息和购买习惯数据进行综合分析,勾勒出不同地区不同时期的消费者的用户画像,为烟草行业的产品设计、新品研发[5]、区域个性化定制、营销策略、经营措施、管理决策等提供支持。



