刘向东,王晓光,邹 密
(吉林大学公共计算机教学与研究中心,吉林 长春 130012)
引言
自动驾驶技术是近年来的研究热点[1]。为了满足车辆的安全性,可实用的自动驾驶系统需要根据不同的交通状况进行测试,美国兰德智库的估算,这需要110 亿英里以上的实地验证[2]。这意味着,如果100 辆测试车以时速25 英里每小时全天不停车测试,也要花费数百年的时间。所以通过仿真系统,实现自动驾驶算法的验证是技术落地的必经之路。
自动驾驶仿真系统,需要为算法提供尽可能真实的场景,包括行人、车辆、障碍物等不同情况的交通模拟,还要允许在暴雨、强光和傍晚等不同天气条件下进行测试。自动驾驶算法则需要在环境中实现感知、定位、决策和控制等所有步骤。现有的仿真系统,大都追求全过程个性化模拟[3-4],缺乏对驾驶决策,这个自动驾驶算法的核心内容的专向设计,从而提高了系统和实验的复杂度。
强化学习是机器学习领域中,用来解决智能体在不确定的复杂环境中优化决策以获取最大化奖励的问题。与传统的决策算法相比,能够处理无模型的动态规划情况[5],非常适合在复杂环境下的实现自动驾驶决策。本研究基于UE5 引擎和Airsim 框架,针对自动驾驶的决策过程,设计并实现了仿真平台和实验情景,简化了感知、定位和控制接口,使用python 语言为强化学习过程设计了代码框架。仿真平台实现了使用强化学习算法,针对从端到端的自动驾驶应用的简单测试流程,也可应用于机器学习的教学和实验。
1 仿真平台总体结构
为了达到L4 级别以上的自动化等级,需要被驾驶车辆能够实时监测周围路况,获取图像、距离、位置等信息,作为决策依据,通过程序控制实现导航、避障等指定任务,消除人工干预。由于在整个过程中,决策程序属于观察者的角色,而环境、车辆、交通、传感器数据可以独立的自主运行。所以,仿真实验平台被设计为服务器- 客户端的运行模式,决策系统位于客户端。
服务器端在Unreal Engine5(UE5)游戏引擎上开发,主要实现环境布局、模型展示和多种天气条件等真实世界的模拟。UE5 提供了最先进的渲染质量和逼真的物理效果,让虚拟环境在物理和视觉上都实现真实模拟。为了体现行人、车辆、交叉路口等交通情况的复杂性[6],服务器借助MassAI 组件生成大量可自主运动的人和车辆的智能体,以模拟交通系统。
客户端基于微软的开源模拟器Airsim 实现对无人机器和交通系统的程序控制。Airsim 支持基于PX4[7]等飞控固件的实时在环仿真,可以对无人机、车辆模拟真实的手动控制[8]。Airsim 也提供了API 接口,通过TCP 协议与服务器端进行通信。仿真平台基于Airsim,为用户在客户端生成了Python 接口,用于服务器中的车辆的生成、传感器设置和交通系统的控制。此外,为了实现强化学习算法测试,还需要为强化学习设计Python 接口以实现对自动驾驶和其他任务的训练和测试。
最后,仿真平台为强化学习决策设计了4 个实验情景模块:目标识别、搜寻、避障、自动驾驶和手动控制,见图1。其中,手动控制模块是为强化学习中的模仿学习框架准备的,可以应用到其他实验情境中,为其提供初始的动作决策。为了更有效的用于实验和测试,平台设计了像素流送和VR 演示方法,方便在桌面、移动设备或VR 设备上进行体验。
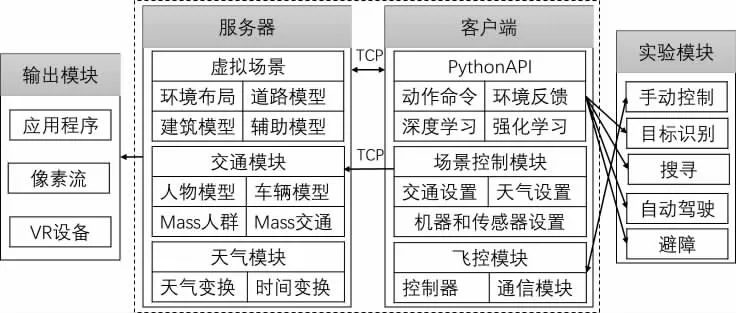
图1 自动驾驶仿真教学实验平台结构
2 服务器端设计
2.1 虚拟场景设计
理想的模拟器应该尽可能的真实,全局环境的布局最好能来源真实地图,对此平台使用Cesium 软件实现该想法。Cesium 是一款3D 地理空间开发系统,根据真实地图的提供了高精度的地形和影像服务。平台先从Cesium 中依据经纬度选择目标城市部分区域的地形和云端的3D 内容作为虚拟场景模板,再用真实材质和高精度模型替换模板中的失真和缺失信息。
此外,由于UE5 中可以直接使用Quixel 三维模型库,在Quixel 中可以找到数千个由真实世界扫描获得的高仿真模型,用这些模型填补生成环境中的树木、道路、房屋等复杂对象。使得静态仿真环境更加的真实。同时,高仿真模型的渲染带来的更多计算量的需求,为了优化显示过程,采用了UE5 中的Nanite 虚拟化几何体系统,通过将大量模型转换为Nanite 网格体,减弱了对用户硬件资源的需求。
最后,自动驾驶的需求可能出现在不同天气和光照条件下,对于基于图像的驾驶策略训练来说,天气模拟就显得非常重要。平台根据天气和时间变换,提供了可定制的雨、雪、晴天、日初、夜晚等多种环境选项,可在开始菜单或客户端脚本中设置。(见图2)

图2 不同天气条件下的仿真平台
2.2 人群和交通模拟
为了让仿真平台具有更多的互动性,使虚拟世界活动起来,平台采用了UE5 为大规模生成智能对象的MassAI系统。整个Mass 框架分为三部分:MassEntity,MassGameplay 和MassAI。其中MassEntity是一种面向数据的框架,将所有处理逻辑与数据构成进行分离,可以增强数据和代码的一致性,简化未来的并行执行。Mass GamePlay 能够将大量的实体带入虚拟世界。包含生成可视化的Spawner 组件和LOD 机制。其中Spawner 通过区域图确定实体的生成位置,通过区域图连接在一起的逐点廊道结构,定义生成位置和AI 行为。
在平台设计过程中,需要为每条人形道路和行车路线分别定义区域图,并指定不同颜色的标签,用于引导人群和车辆的生成,见图3。最后通过MassAI 为智能体添加运行轨迹。为了体现真实环境中的随机性,通过随机生成区域图和行为的方式,添加行人非正常交通。

图3 在场景中用区域图实现人群和交通模拟
在Mass 框架中,人群与交通系统存在着一定的区别。人群使用状态树,描述当前实例可能出现的所有状态,即控制AI 的行为,如漫步、闲逛、避让等。车辆交通系统中,则没有使用状态树。所有行为都在Mass Processor 以编程的方式生成。如沿着车道陆续前进,会沿着车道排列车辆。为避免车辆相撞,车辆会检测到前车的距离,并根据距离调整车速。
3 客户端设计
客户端是用于对虚拟环境进行配置和程序控制的API 框架,使用python 语言通过TCP 协议与服务器端进行通信。针对实验情景,服务器端提供了默认的情景生成:让被控车辆和车载摄像头、雷达、IMU、GPS 等多种传感器的定点生成。同时也可以通过场景参数定制实验情景,并提供简单控制和基于PX4 固件的仿真控制两种方案,以便获取初始动作。
客户端需要服务器的支持才能运行,允许向服务器发送场景参数,设置场景中的交通系统、天气情况和传感器等初始信息,发送油门、转向等控制命令,同时通过传反馈值,修正自动驾驶策略,以驱动无人机器完成指定任务。一个服务器可以同时支持多个客户端在线运行,在场景中实现多用户协同操作。
3.1 实验模块设计
在仿真平台中,为面向强化学习策略的自动驾驶设计了5 个情景任务模块。包含任务目标、达成目标、默认参数等信息。可以通过客户端设计python 脚本完成任务。
(1) 手动控制:场景中允许用户直接控制服务器中车辆,完成目标点A 到目标点B 的有障碍驾驶,将用户的操作记录为初始动作,通过模仿学习优化控制流程。
(2) 自动导航:固定路线和非固定路线的自动驾驶,实现从目标点A 到随机目标点B 的自动路径规划和驾驶,无移动障碍物,有时间限制。
(3) 避障:开启人群和车辆交通模拟后,从目标点A 驾驶到随机目标点B,完成有移动障碍物的跟随及自动导航,要求无碰撞,有时间限制。
(4) 搜寻:在自动驾驶过程中,从摄像头传感器中识别并标识出目标对象,再通过程序控制车辆搜寻目标对象。
3.2 强化学习实验接口设计
强化学习算法本质上,是通过在不断试错中获取环境中的奖励或惩罚,作为反馈从而指导智能体更好的与环境交互,最后获得最大收益的过程[9],见图4。由于强化学习具有与陌生环境独特的试错方法和反馈机制,所以很早就应用到智能交通系统,如结合多智能体的Q-Learning 算法解决交通信号控制问题。但传统的强化学习算法,应用于情况复杂,拥有高维输入数据的真实环境,实现具有连续动作空间的自动驾驶领域,效果就不够理想。
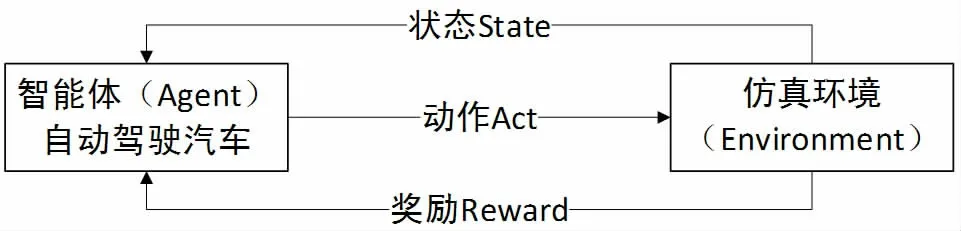
图4 强化学习框架
随着深度学习在计算机视觉等领域取得了成功,使用深度神经网络对高维数据进行降维,再完成强化学习过程,为解决复杂问题提供了更好的思路。实际上,使用深度强化学习算法,如DQN、DDPG 等,已成为训练一个从端到端的自动驾驶模型的常用方法。通过对图像、深度传感器和激光雷达等场景输入数据提取特征,再控制车辆加速、转向、制动等行为完成自动驾驶过程。
如果要专注于决策过程,简化感知、定位和控制等步骤的设置,无论采用哪种强化学习算法,都需要考虑训练目标、训练方法和系统反馈的标准化。在客户端中将服务器的通信结果标准化到如下的状态-操作动作空间:
(1) 允许强化学习算法发送动作指令操控车辆在仿真环境中行进。在接口程序中为车辆提供油门、转向和刹车3 个参数,值域分别为【0,10】、(-1,1)、【0,1】。通过修改三个参数的值实现对车辆的程序控制。
(2) 能够获取被控制车辆的实时状态。车辆的速度、位置和是否碰撞等信息,不使用Slam 等定位方法,而是直接通过服务器直接传递被控车辆的状态信息。
(3) 能够得到奖励反馈。自动导航、避障和搜寻实验都为半固定路线的自动驾驶场景,可以预先在服务器中及算出推荐的行进路线,以速度快、偏离推荐路线少作为正向奖励,以负数作为发生碰撞,反向行驶,超出预定时间的惩罚。奖励函数如下

其中,vx为车辆延预定道路纵向轴线的速度,θ 为车辆的航向角,ε 为偏移距离。
强化学习的训练框架,也需要由python 定义一个Experiment 类实现,其中包括用于重置环境的Reset函数、每轮训练的代码接口Step 函数,以及用于计算奖励的Reward 函数等。训练过程的python 伪代码如下

4 结论
本研究设计的自动驾驶仿真教学实验平台,通过建立高精度、可定制、高互动性的仿真环境,拉近了虚拟和现实的距离。既可以作为一个通用性的自动驾驶训练平台,也为驾驶决策过程,实验和测试算法,提供了简化的、端到端的平台。具有较强的实用性和可拓展性,为仿真平台设计提供了一种思路。



