刘月恒 黄惠 吴迪* 邱显荣 张青川
1.太和康美(北京)中医研究院有限公司 北京 102445;2.北京工商大学电商与物流学院 北京 100048
1 概述
随着人们生活水平不断提高,化妆品行业也得到越来越多人的关注。当前化妆品标准中的文本以及关键信息分布较为分散,这些信息多是独立存在的,通过构建化妆品标准知识图谱可以有效地将这些信息关联起来,能够为国家监管部门提供辅助决策支撑。
实体关系抽取是构建知识图谱的关键技术,早期关系抽取任务主要有两种,一种是基于规则[1-3]的方法,通过人工设计的一些规则来抽取实体关系三元组,主要包括基于触发词和基于依存关系的两种方式;另一种是利用机器学习[4-5]来抽取实体和关系,主要依赖一些工具来提取文本的特征。基于机器学习的方法以数据集标注量又可以划分为有监督、半监督和无监督的方法。基于规则的方法由于需要进行规则制定,这就导致需要花费大量的人力,并且对于信息量大以及文本结构复杂的信息很难进行有效处理。利用机器学习的方法可以有效解决基于规则的方法存在的不足,并且其应用也更加广泛,但是该方法需要通过人工来进行特征提取,仍然存在泛化能力不足的缺点。
随着深度学习的不断发展,越来越多的学者开始采用深度学习的技术来提取文本中的实体和关系,这有效克服了机器学习的方法需要进行人工特征提取的不足,同时准确率也获得了进一步的提升。参考文献[6]中的学者提出一种基于SDP-LSTM的关系抽取模型,该模型可以利用最短的依赖路径迭代地学习关系分类的特征。同时,利用LSTM单元进行远程信息传播和集成。参考文献[7]中的学者提出了一种基于BERT的医学关系提取模型,该模型将从预先训练的语言模型中获得的整个句子信息与两个医疗实体的对应信息相结合,完成关系提取任务。丁泽源等[8]提出了一种pipeline的中文生物医学实体关系抽取系统,并且取得了较好的实验结果。但是相比于公共的一些数据集,化妆品行业数据就有其独特性,语料中存在大量的行业术语和专业名词,这也是进行实体关系抽取的一大难点,基于此本文提出了一种融合注意力机制的BERT-BiLSTM-Attention-CRF的实体关系抽取模型,能够有效地提取化妆品文本中的实体和关系信息。
2 模型
针对化妆品标准存在大量专有名词以及语义稀释等问题,我们提出了融合注意力机制的BERT-BiLSTM-Attention-CRF化妆品标准实体关系提取模型,模型的整体结构如图1所示。包含BERT、BiLSTM网络层、Attention注意力机制和CRF层四部分。
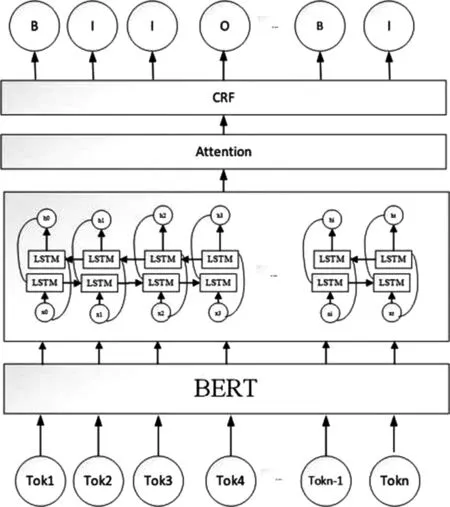
图1 BERT-BiLSTM-Attention-CRF
2.1 BERT
BERT[9]预训练语言模型采用12层Transformer编码器进行编码,该模型可以学习到输入序列的特征表示,然后再把学习到的特征表示应用到不同的下游任务中。BERT的预训练模型包括两个训练任务,Masked LM任务用来捕捉单词级的特征,Next Sentence Prediction任务用来捕捉句子级的特征。在化妆品标准的实体关系抽取任务中,化妆品标准文本结构更加复杂,语义也较为稀疏,相较于RNN,BERT能够更好的捕捉上下文的文本特征,所以可以进一步提升实体识别的效果。
2.2 BiLSTM层
LSTM是一种特殊的循环神经网络模型,允许每个神经单元忘记或保留信息,克服了RNN在自然语言处理任务中容易出现梯度消失和梯度爆炸问题,具有长时记忆功能。但在化妆品标准文本中,一些专有名词通常包含较多的字符,并且前后文之间有较强的依赖关系,所以本文采用了BiLSTM模型,BiLSTM接收BERT输出的向量作为输入,从而获得更加全面的语义信息。BiLSTM对每个训练序列应用一个前向和后向LSTM网络,两个LSTM网络连接到同一个输出层。
LSTM网络结构包含输入门、遗忘门和输出门。模型的计算公式如下所示:
it=σ(Wi·[ht-1,Xt]+bi)
(1)
ft=σ(Wf·[ht-1,Xt]+bf)
(2)
(3)
ot=σ(Wo·[ht-1,Xt]+bo)
(4)
(5)
ht=ot*tanh(Ct)
(6)
其中,Wi、Wf、Wo是加权矩阵,bi、bf、bo是LSTM的偏差。it表示t时刻的输入门,ft代表t时刻的遗忘门,ot分别代表t时刻的输出门,Xt表示t时刻的输入,ht和表示t时刻的输入向量输出。
2.3 Attention注意力机制
注意力机制就是对输入的不同元素考虑不同的权重参数,从而更加关注与输入元素相似的部分,而抑制其他无用的信息。注意力机制可以在资源有限的情况下快速、准确地处理信息。由于在化妆品标准文本中存在语义稀疏的问题,通过引入注意力机制对提取的特征进行分配不同的权重,得到单词重要性的文本特征表示,可以进一步提升模型的性能,并且能有效解决BiLSTM存在的不足。
2.4 CRF编码器
条件随机场(CRF)[10]是一种以指定的随机变量为输入,解决随机输出变量的条件概率分布的算法。CRF接收BiLSTM和Attention输出的特征向量作为输入,进行序列标注。CRF通过学习标签之间的依赖关系,保证了标签的有效性,从而得到最优的标签序列。CRF的基本算法定义如下:
(7)
(8)
其中BiLSTM层的输出结果定义为Pmn,其中n表示单词数,m表示标签类别。其中,Pij表示第i标签与第j个标签匹配的概率。对于输入的句子序列X={x1,x2,…,xn}及其预测的序列Y={y1,y2,…,yn}。
3 实验
3.1 数据集与数据预处理
实验所用的数据集来源于化妆品标准,由于缺少相应的公开数据,本实验采用爬虫技术从食品伙伴网以及国家药品监督管理局等网站采集并通过人工校对,构建了化妆品标准数据集(CSD)。并将该数据集分为训练集、测试集和验证集,各子集的数据量见表1。

表1 实验数据集
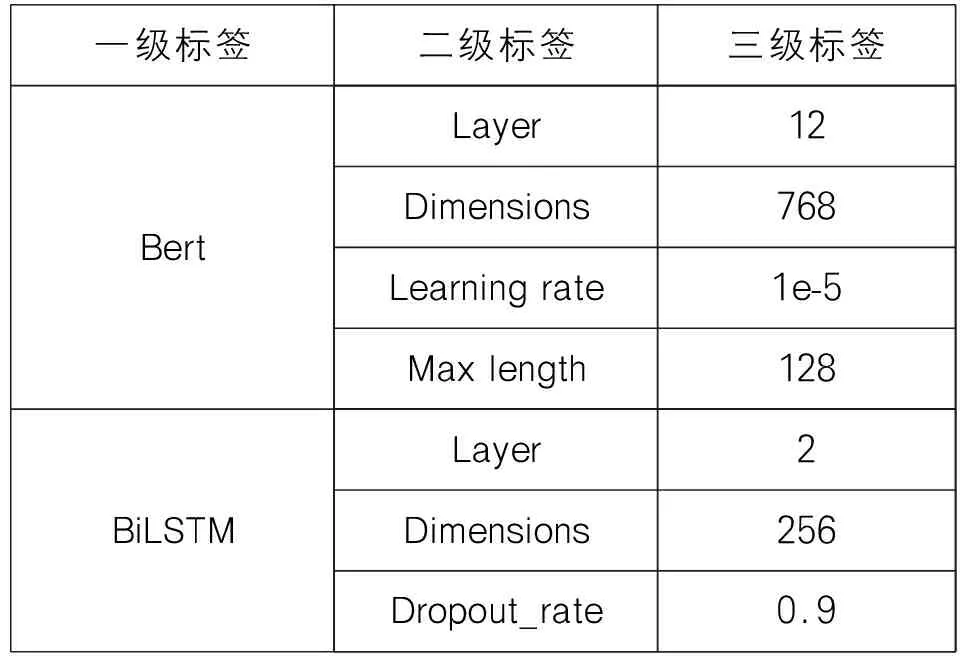
表2 实验参数设置
3.2 实验参数设置
3.3 评价指标
本文采用三个常见的指标,即精度(P)、召回率(R)和F1来评估我们的模型。计算公式如下:
(9)
其中P代表精确度,TPi表示实际正类,预测也为正类的数量,FPi表示实际负类,预测为正类的数量。
(10)
其中R代表召回率,TPi表示实际正类,预测也为正类的数量,FNi表示实际正类,预测为负类的数量。
(11)
其中P为精确度,R为召回率。
3.4 结果分析
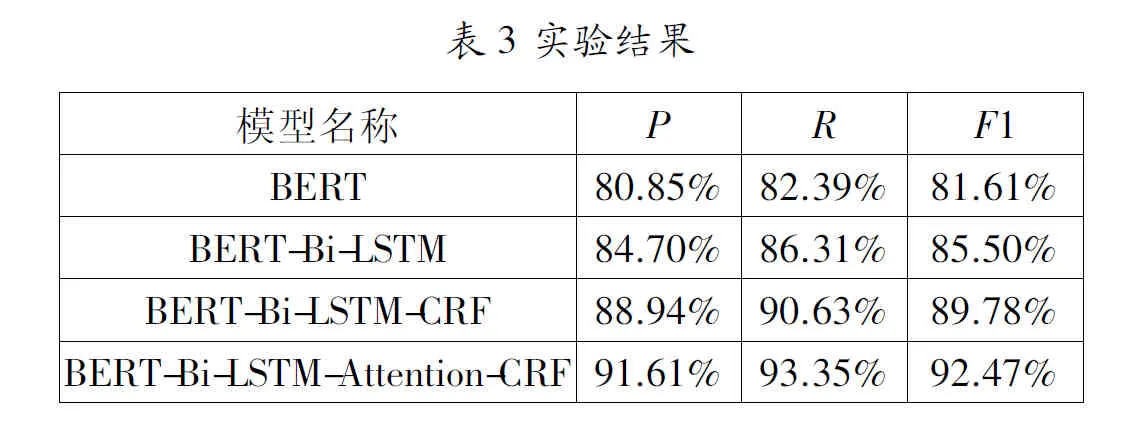
结果表明,在未引入自注意力机制情况下,BERT-BiLSTM-Attention-CRF模型的准确率、召回率、F1值分别为88.94%、90.63%、89.78%。在BiLSTM后面引入注意力机制以后,可以看到实体关系抽取结果有了进一步的提高,准确率、召回率和F1值分别提升了2.67%、2.72%和2.96%,说明我们模型有效提升了实体关系抽取整体效果。相比于BERT模型,BERT-BiLSTM模型在F1值上提升了3.99%,这说明BiLSTM在实体关系抽取中发挥了积极作用。BiLSTM可以将输入序列的信息向后组合,有助于提高实体识别效率。BERT-BiLSTM-CRF模型的性能高于BERT-BiLSTM模型,证明了CRF模型可以有效解决标签之间的依赖关系。
结语
本文提出的融合了注意力机制的BERT-BiLSTM-Attention-CRF模型在引入注意力机制以后,可以有效的分配特征权重,排除噪音,提高模型在实体关系抽取中的性能,为构建化妆品标准知识图谱提供参考。同时在BiLSTM后面融合注意力机制可以有效解决在长文本中存在的语义稀疏的问题,但是本文未考虑到文本中存在的实体重叠的情况,这是我们接下来工作的一个方向。



