张 宁,朱晖宇,张宇凡,杜重洋
(1.海装驻上海地区第八军事代表室,上海;2.中国船舶及海洋工程设计研究院,上海;3.上海中船船舶设计技术国家工程研究中心有限公司,上海)
引言
疏浚船通常具有作业量大、功率高、能耗大的特点,其能耗成本占总成本约40%或更高,这对环境造成了极大的负面影响,同时,也给船舶公司的营运带来了很大的负担。另外,疏浚船工况复杂,能效影响因子众多且耦合性强,目前大多是通过船长的个人经验对疏浚船能效进行控制,因此实现疏浚船合理的能效管理关键在于针对疏浚船开展能效分析预测研究。
为了提高分析预测精度,本文在充分考虑疏浚船施工特点的基础上,提出了一种基于耙吸挖泥船在挖泥工况下的LSTM 网络能效分析预测方法,该方法首先利用平滑算法对实船数据进行数据滤波,随后通过相关性分析提取疏浚船能效关键因子,以此作为LSTM 网络的输入,最后进行网络训练,从而实现对疏浚船能效的分析预测。
1 各能效影响因子相关性分析
在得到各工作状态后,分别对影响万方土油耗的各类因素的相关性进行分析。若输入参数过于冗余,则会导致计算的复杂性增加,进而影响模型的准确性,所以选取对分析有利的几个主成分作为输入。为了挖掘万方土油耗与各参数之间的相互影响,本文引用相关性分析来描述各参数与万方土油耗的关联程度进而衡量出参数之间的相关性程度,其计算方法如下:
设X1,X2, …,X p,Y1,Y2, …,Yq分别为两类需要进行相关性评估的参数,X,Y 分别对应两组随机变量,对于各影响参数的两组变量(X1,X2, …,Xp)和(Y1,Y2, …,Yq)寻找一种相对应的线性组合,考虑像主成分分析一样的(X1,X2, …,Xp),一个线性组合U 及(Y1,Y2, …,Yq)的一个线性组合V 合并成一组向量,希望找到和V 之间有最大可能的相关系数以此来充分反映两组变量之间的相关关系。这样就把研究影响因素的两组随机变量间相关关系的问题转化为研究两个随机变量间的相关关系。
待评估的两组向量X=(X1,X2,…,Xp)T,Y=(Y1,Y2,…,Tq)T(p≤q)将两组参数合并成一组向量(XT,YT)=(X1,X2,…,Xp,Y1,Y2,…,Yq)T,合并后参数变量的协方差矩阵为:
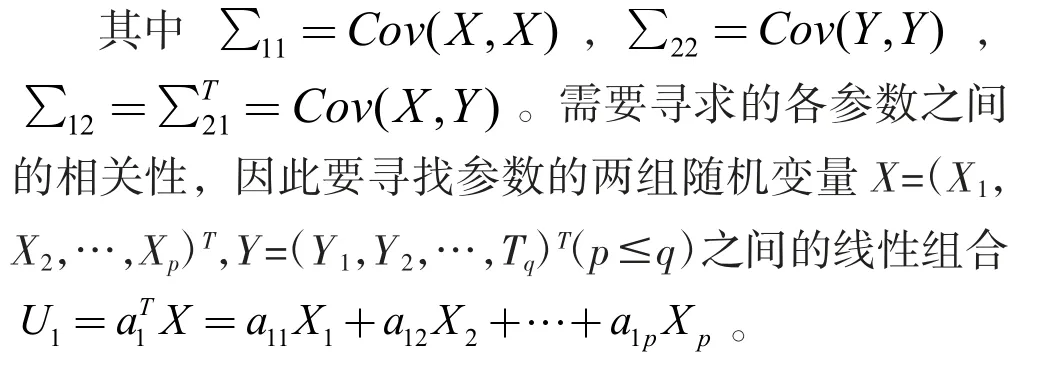
使由X、Y 变化的线性组合U1、V1的相关系数ρ(U1,V1)达到最大,这里各线性组合表达式的系数

本文在挖泥工况下研究各影响因子与万方土油耗的相关性和计算相关性系数,根据相关性分析理论可得,相关性系数的正、负仅代表两个相关参数之间的相关性大小,相关性系数的大小表示参数间的相关性强弱,因此,拟计划采用两个参数的相关性系数的绝对值表示能效参数间的相关性,以表达各参数间的相关性强弱关系。当相关性系数大于0.8,则说明该因素与万方土油耗具有高度相关性;若相关性系数在0.8~0.5 之间,说明具有较大的相关性;若相关性系数在0.5~0.3 之间,说明具有相关性;若相关性系数小于0.3,则为微相关。因此,通过相关性系数分析,可以挖掘出对于万方土油耗影响较高的因素,进而实现对能耗的分析与评估。
耙吸船各影响因子相关性系数见表1。
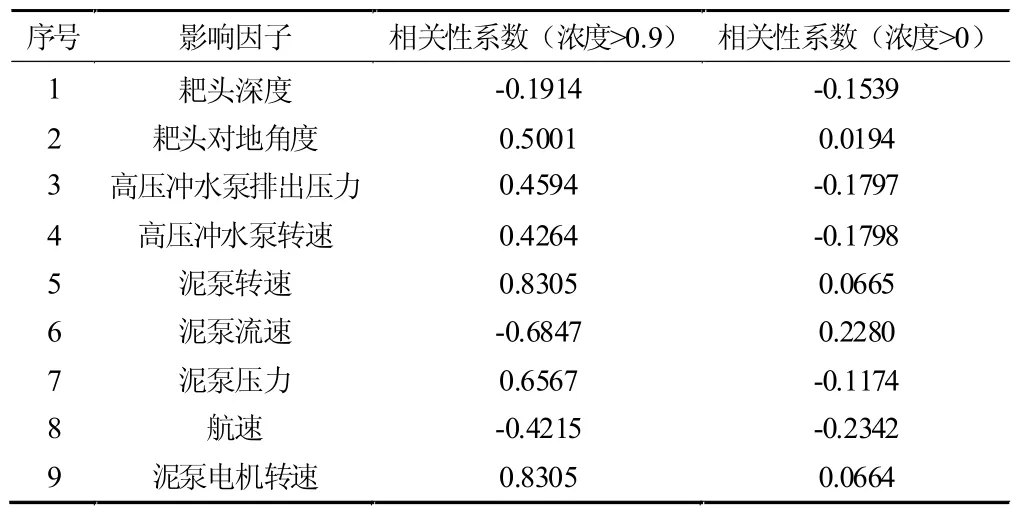
表1 耙吸船各影响因子相关性系数
2 能效预测评估模型
从各能效影响因子相关性分析可知,疏浚船能效关键因子较多,且相互之间耦合性很强。另外,疏浚船在进入挖泥工况下时,各疏浚设备从非工作状态转换至完全工作状态需要一定的时间。二者结合判断,疏浚船能效分析预测是一种复杂的非线性回归问题,且可能还存在时序性因素。
BP 神经网络是一种按照误差逆向传播的前馈神经网络。它利用样本数据通过网络训练即可获得输入-输出之间的映射关系,且数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数,这使得其特别适合于求解内部机制复杂的问题,具有较强的非线性映射能力,同时BP 神经网络在训练时,能够通过学习自动提取输出,并自适应的将学习内容记忆于网络的权值中,具有高度自学习和自适应的能力。
长短时记忆网络(LSTM)在循环神经网络的基础上做了改进,使用LSTM 网络可以有效的传递和表达长时间序列中的信息并且不会导致长时间前的有用信息被忽略,其结构如图1 所示。其中,输入门的作用是决定输入值xt中有多少信息可以吸收进记忆单元。遗忘门的作用是决定上次的记忆信息中要忘掉多少。本次的记忆单元的计算形式为:根据ht-1和xt产生,然后由输入门和遗忘门共同控制t 的记忆值。输出门最终决定t 的记忆值有多少可以输出作为最终的ht+1。整个神经元结构就是根据输入xt和ht-1分别计算四个控制门后再组合运算输出,从而决定“记住多少、忘掉多少、放出多少”。这种算法改进使得神经元的记忆能力更强并解决了传统循环神经网络的梯度爆炸问题[1]。
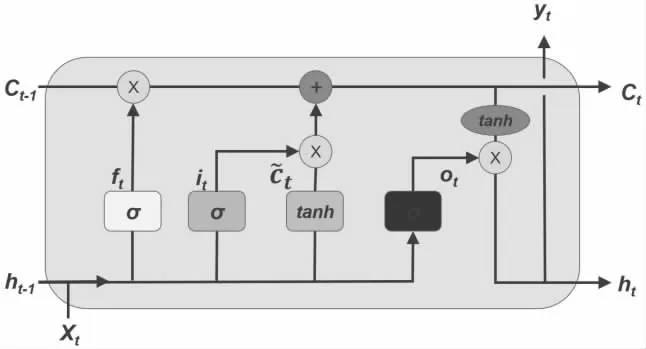
图1 LSTM 网络结构
BP 神经网络的输出值只与当前的输入值有关,即只要是完成训练的网络模型,其输入值和输出值的关系是固定的和明确的,这种性质在处理疏浚船挖泥过程这种存在时间序列数据的预测问题时是有缺陷的。序列数据的预测问题中,下一个值的出现概率并不直接由当前值决定,而是由当前值和前面若干个值共同决定。即一系列的数据才能决定下一个值出现的概率[2-4]。因此,在原理分析上,LSTM 网络更适合解决当前问题,本文拟采用LSTM 网络作为疏浚船能效分析预测的备选算法。
3 耙吸船能效仿真分析
3.1 数据处理
由于疏浚船实船数据包含非工作状态数据,因此在能耗分析过程中对数据进行了筛选,即剔除无效数据。但筛选后的数据仍然含有噪声,因此分别利用高斯滤波、均值滤波和中值滤波3种平滑算法对疏浚船数据进行降噪,并通过后续模型拟合的效果对比,选择最优的数据处理方法。
高斯滤波是一种信号的滤波器,适用于消除高斯噪声,即概率密度函数服从高斯分布(正态分布)的一类噪声,广泛应用于数据处理的减噪过程中;均值滤波被称为线性滤波,其采用的主要方法为邻域平均法。线性滤波的基本原理是用均值代替原数据中的各个值;中值滤波法是一种非线性平滑技术,它将每一数据点的值设置为该点某邻域窗口内的所有数据点值的中值。
在数据降噪后,将数据归一化预处理,并按时间顺序排列,组成新的时序数据,再进行能耗预测。数据预处理的流程如图2 所示。
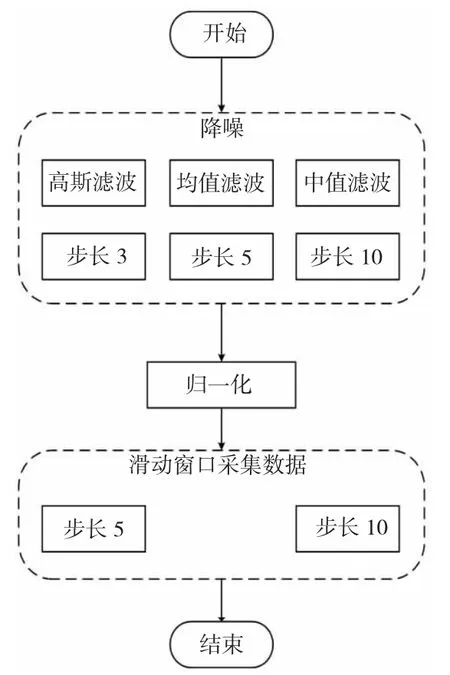
图2 数据预处理流程
3.2 BP 与LSTM 神经网络能耗预测对比结果
为了比较LSTM 神经网络和BP 神经网络对耙吸船的挖泥过程数据的拟合能力,项目分别利用BP 神经网络和LSTM 神经网络,对该数据的油耗值进行拟合。图3和图4 分别为BP 神经网络拟合模型和LSTM 神经网络拟合模型的预测结果与真实值的对比。可以看出,由于耙吸船的挖泥过程数据是一段时间序列数据,当前时刻的油耗值不仅仅与此时的耙吸船工作状态相关,也与之前时间耙吸船的工作状态和油耗值相关。而LSTM 神经网络的特殊结构使得当前时刻的网络输出值与过去时刻的网络输入值和输出值都相关,对油耗值的变化趋势较BP 神经网络有更强的判断能力,大大提高了拟合效果。
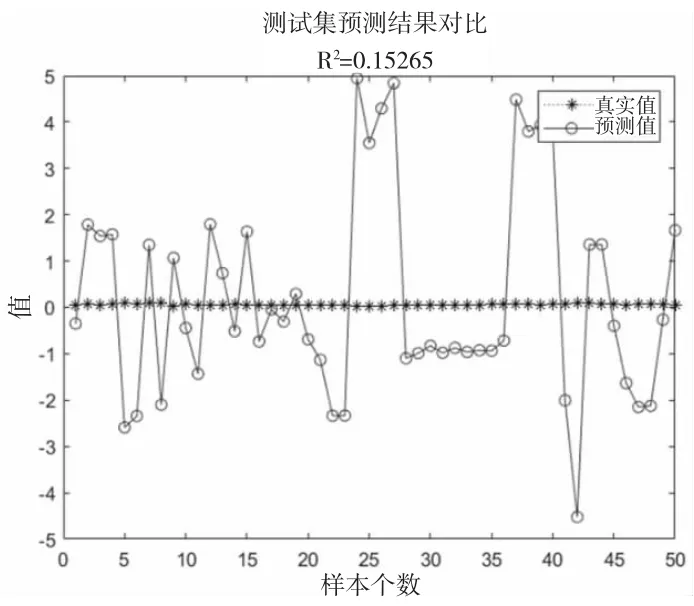
图3 BP 神经网络拟合效果
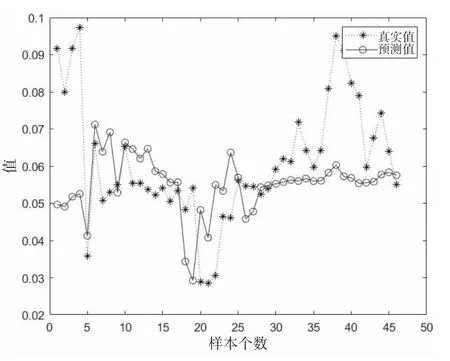
图4 LSTM 网络拟合效果
3.3 数据降噪与LSTM 神经网络拟合
项目分别采取滑动窗口大小为3,5,10 的高斯滤波、均值滤波和中值滤波算法对所有数据降噪,来提高拟合的准确性。在对数据降噪处理后,利用一定长度的滑动窗口将时间序列数据采集、并输入到LSTM 网络中拟合。其中,滑动窗口的长度选择选取5 步和10 步。
均方误差值是反映估计量与被估计量之间差异程度的一种度量,在本项目中作为拟合效果评价指标。对于不同降噪算法,不同的滑动窗口步长,算法的整体拟合效果对比报告如表2、表3、表4 所示。
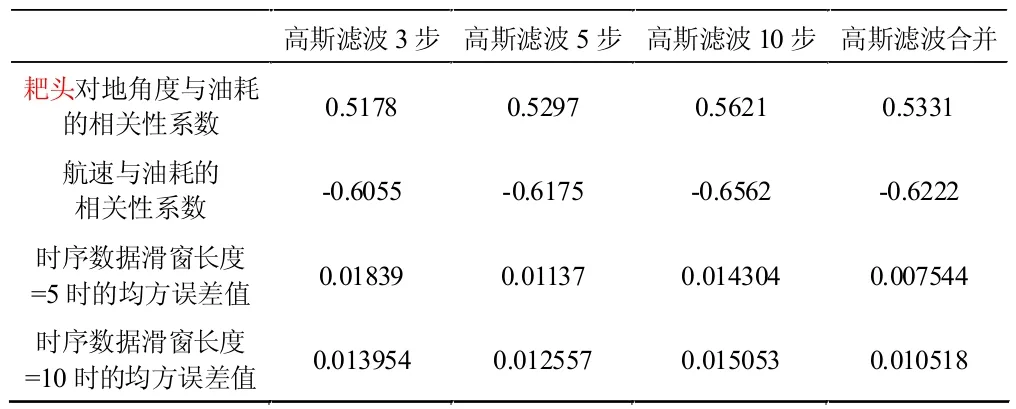
表2 高斯滤波拟合效果对比报告
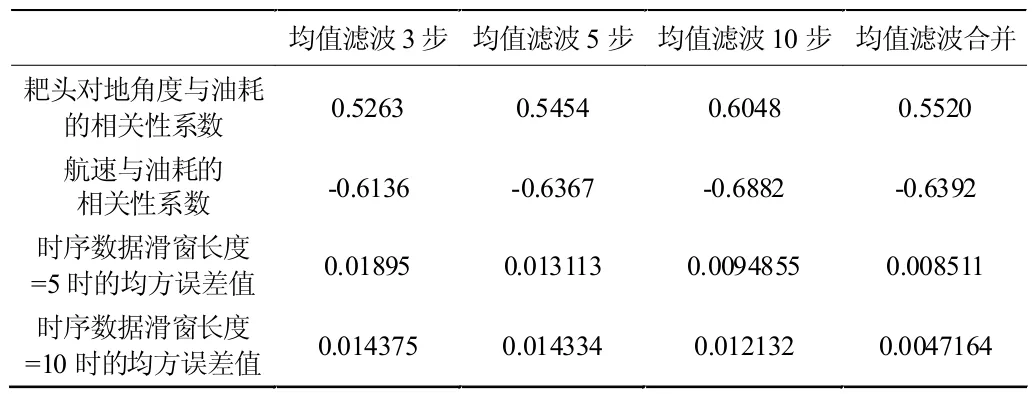
表3 均值滤波拟合效果对比报告
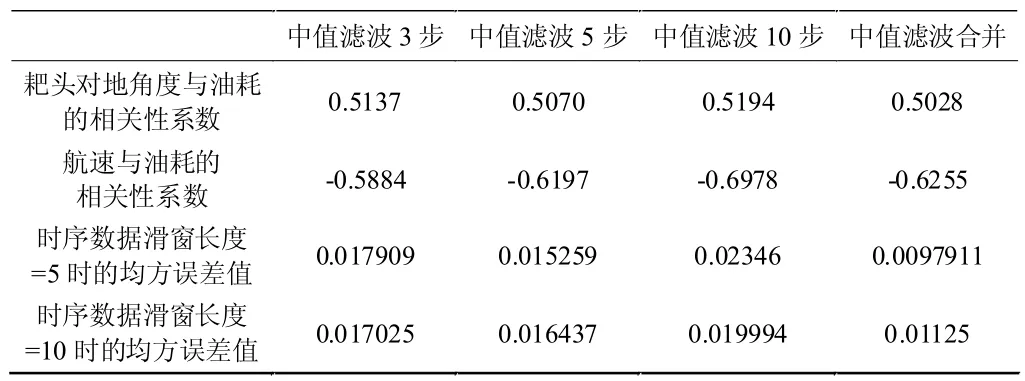
表4 中值滤波拟合效果对比报告
由表2、表3、表4 可以得出以下结论:(1)最优参数组合:平滑方法采取将步长为3、5、10 的均值平滑数据合并,时序数据步长采取5 步时,均方误差值小于其他参数情况。在该参数下的拟合效果如图5 所示。(2)平滑算法对比:均值平滑效果最优,中位数平滑效果最劣。将不同步长数据集组合成新数据集,此时数据集个数提升了,准确率也因此提升。(3)LSTM 时序数据步长对比:时序数据的步长设置对结果影响不大。(4)相关性系数对结果的影响:大多数情况下,数据的相关性系数越高,拟合效果越好。
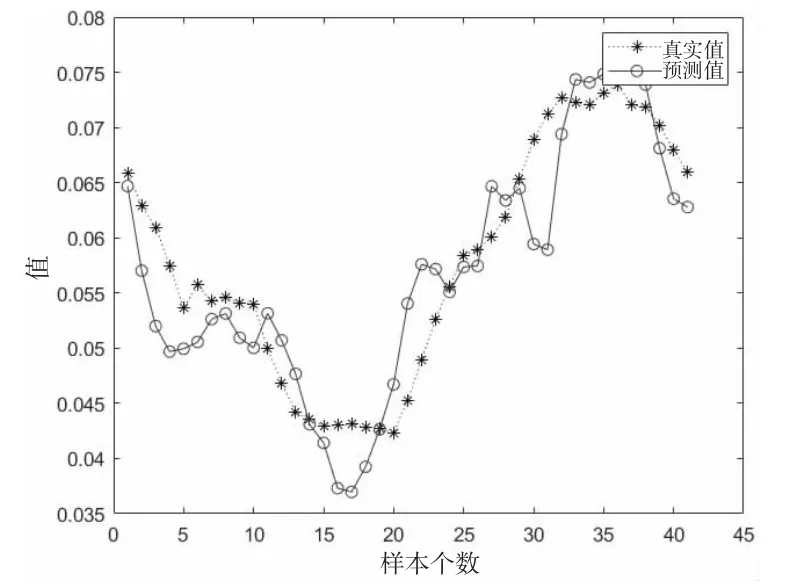
图5 最优参数组合效果
4 结论
从耙吸船各能效影响因子相关性分析可知,其能效关键因子较多,且相互之间耦合性很强,同时,耙吸挖泥船在作业工况下,其能效分析预测是一种复杂的非线性回归问题,本文通过对比分析BP 神经网络和LSTM 神经网络的预测结果,验证了该应用场景下存在时序性因素,并且在采用时序数据步长为5 的均值滤波数据降噪方法时,利用LSTM 神经网络拟合模型的预测结果最优。



